本文最后更新于 2026年1月28日 晚上
信息论与编码 cheat sheet
信息论与编码
引论
信息论的基本概念
- 信息论:一门应用概率论和数理统计的方法研究概率信息的传输、存储和处理的学科
graph LR
A[信源]-->|消息|B[编码器]
B-->|信号|C[信道]
C-->|信号|D[译码器]
D-->|消息|E[信宿]
F[干扰源]-->|干扰|C
-
信息
-
信息、消息和信号
- 信息:抽象,包含在消息中
- 消息:具体,但不是物理的,可以包含多个信息
- 信号:消息的载荷者
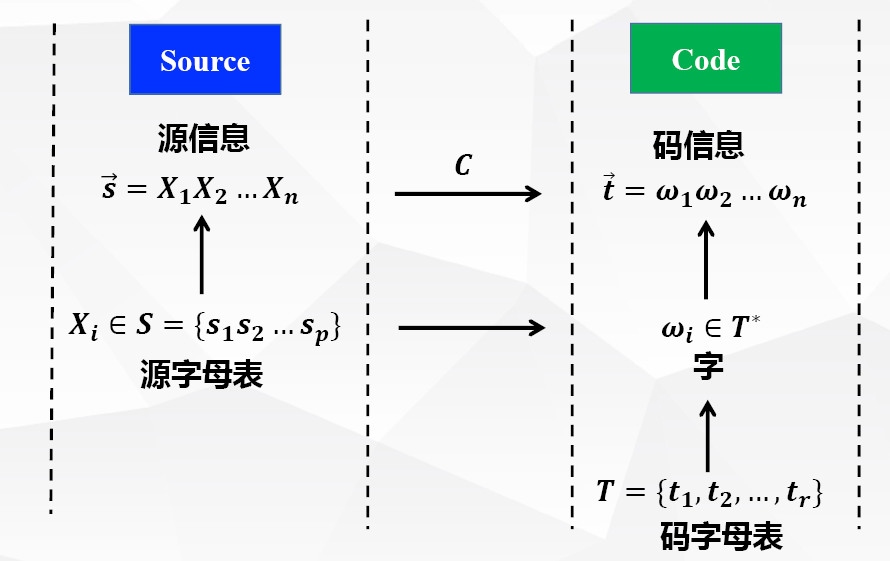
信源编码:唯一可译码
信源的数学模型
-
(离散)信源:信源每隔一个定长时间段就发出一个随机变量;随着时间的延续,信源发出的是随机变量序列 X1,X2,X3,…
-
假设每个 Xn 都是一个取值在有限集合 S={s1,s2,s3,…} 上的离散型随机变量
-
实际中认为信源序列有限,但是出于理论证明的目的,也会考虑无限长序列
-
分类
- 离散无记忆信源:随机变量 X1,X2,X3,… 彼此统计独立
- 离散无记忆简单信源(教程主要信源):随机变量 X1,X2,X3,… 具有相同的概率分布
信源编码
-
r-元编码
- 假设每个 Xn 都是一个取值在信源字母表 S={s1,s2,s3,…,sq} 上的离散型随机变量
- 设有一个含 r 字母的字母表 T={t1,t2,t3,…tr}, 对于 (X1,X2,X3,…) 的每一个事件,都用一个字母串来表示,这种表示方法称为 r-元编码;
- e.g:r=2,ASCII;r=3,Morse code
-
字:T 中的一个字 w 是由 T 中字母组成的有限序列,字的长度即为序列中字母的个数
- Tn=T×T×T×⋯×T:长度为 n 的字的集合
- ε:长度为 0 的空字
- T∗=⋃n≥0Tn:所有字(包括空字)的集合
- T+=⋃n>0Tn:所有非空字的集合
-
信源编码:C:S→T+,简记 C={ω1,ω2,…,ωq}
-
信源序列编码:C∗:S∗→T∗,简记 C∗={ωi1,ωi2,…,ωin∈T∗∣ωij∈C,n≥0}
-
平均码字长度:设信源随机变量 X 的概率分布为 {ak,p(ak),k=1,⋯,K} ,事件 ak 对应的码字长度为 lk,则平均码字长度为 L(C)=∑k=1Kp(ak)lk=∑k=1Kpklk
- 信源编码的主要目的在于易于实现和码字的平均长度最短
-
唯一可译性:对于一个码,如果存在一种译码方法,使任意若干个码字所组成的字母串只能唯一地被翻译成这几个码字所对应的事件序列
唯一可译码
即时码
-
延时译码:等到序列全部接收完毕后才能开始译码
-
即时码:若对每个码字序列 wi1,wi2,⋯win,每个以 wi1,wi2,⋯win 开头的码字序列 t 都
唯一地被译为 s=si1si2⋯sin⋯,无论 t 中后续字母是什么。该码称为即时码。
-
前缀码:若每个码字 wi 都不是其他码字 wj ,的前缀,即 wj=wiw,wϵT∗, 等价地, C1=∅
-
一个码 C 为即时码的充分必要条件是 C 为前缀码
唯一可译性的两种解决方法
- 逗点码
- 事件与码字一一对应;
- 每个码字的开头部分都是一个相同的字母串;
- 这个字母串仅仅出现在码字的开头,不出现在码字的其它部位,也不出现
在两个码字的结合部。
- 即时码
- 事件与码字一一对应;
- 每个码字都不是另一个码字的开头部分(字头)
信源编码的分类
graph TD
A(码)-->B1(奇异码)
A-->B2(非奇异码)
B2-->C2(非唯一可译码)
B2-->C1(唯一可译码)
C1-->D1(等长码)
C1-->D2(变长码)
D2-->E1(前缀码)
D2-->E2(逗点码)
即时码的构造
码树
- 一个码 C 可以看做是树 T∗ 中一些顶点的有限集合
- 一个码字 wi 是 wj 的前缀当目仅当存在一条从 wi 到 wj 的向上的路( wi 被 wj 支配 )
- 一个码 C 是即时码当目仅当对每个码字 wi 都不受其他码字 wj(i=j) 支配
Kraft 不等式
- 定理 : 设信源消息集合为 S={s1,s2,…,sq}, 信道基本符号的种类为 r, 码字集合为 C={w1,w2,…,wq}, 对应的码长集合为 b={l1,l2,…,lq}, 则存在即时码的充分必要条件是:r 、 q 和码长 li 应满足如下不等式
i=1∑qr−li≤1
上式称为 Kraft 不等式
※:Kraft不等式只涉及即时码的存在性问题,可以用来判断一组码不是即时码,而不能判断一组码是即时码
McMillan’s不等式
- 定理:任意唯一可译码的长度必然满足Kraft不等式
- 说明:从码字长度集合的角来考虑 ,唯一可译码不能提供比即时码更优的选择 。对唯一可译码和即时码而言 ,其码字长度集合的可行条件是一样的
- 所以目标是:构造平均长度最小的即时码
即时码的最小期望长度问题
-
即时码的最小期望长度问题是一个最优化问题 :
在所有整数 l1,l2,…,lq 上,最优化
L(C)=i=1∑Npili
其约束条件为 ∑i=1qr−li≤1
- 方法:取消对整数的限制 ,利用 Lagrange 乘子法
- 从理论推导可知:最佳码长原则满足:大概率对应短码长,小概率对应长码长
Huffman编码
最优码
二元 Huffman 编码
二元 Huffman 编码的平均码长
- 将信源 S 缩减为 S(q−1) 时产生的 “新”概率之和 p′+p′′+⋯+p(q−1) 即 为编码 C 的平均码长
二元 Huffman 编码的最优性
- 对于任意信源 S,若 C 是与之对应的二元 Huffman 编码,则 C 是信源 S 的最优码
信息量
非平均互信息量
输入、输出空间定义
- 输入空间 X={xk,k=1,2,…,K},概率记为 Q(xk),称为先验概率
- 输出空间Y ={yj,j=1,2,…,J},概率记为 Ω(yj)
- 联合空间 XY={xkyj;k=1,2,…,K;j=1,2,…,J},概率为 P(xkyj)
P(xkyj)=P(xk∣yj)Ω(yj)=P(yj∣xk)Q(xk)
- P(xk∣yj) 称为后验概率
非平均互信息量认识
-
先验概率越大 ,得到的信息量越小 ,反之信息量越大
-
在一个系统中我们所关心的输入是哪个消息的问题 ,只与事件出现的先验概率和经过观察后事件出现的后验概率有关
-
非平均互信息量:给定一个二维离散型随机变量
{(X,Y),(xk,yj),P(xk,yj),k=1∼K;j=1∼J}
因此就给定了两个离散型随机变量 {X,xk,Qk,k=1∼K} 和 {Y,yj,Ωj,j=1∼J}
事件 xk∈X 与事件 yj∈Y 的互信息量定义为 I(xk;yj)
I(xk;yj)=logaQ(xk)P(xk∣yj)=logaΩ(yj)P(yj∣xk)=I(yj;xk)
-
其中底数a是大于1的常数,常用a=2或a=e
- 当 a=2 时互信息量的单位,为 bit
- 当 a=e 时互信息量的单位,为 nat
-
另一种理解:
I(xi;yj)= [收到 yj 前 , 收信者对信源发 xi 的不确定性]−[收到 yj 后,收信者对信源发 xi 仍然存在的不确定性]= 收信者收到 yj 前后,收信者对信源发 xi 的不确定性的消除
-
当事件 yj 的出现有助于肯定事件 xk 的出现,即
P(xk∣yj)>Q(xk), 则 I(xk;yj)>0
当事件 yj 的出现告诉我们事件 xk 的出现可能性减少 , 即
P(xk∣yj)<Q(xk), 则 I(xk;yj)<0
-
三个事件集的条件互信息定义为
I(u1;u2∣u3)=logp(u1∣u3)p(u1∣u2,u3)=logp(u1∣u3)p(u2∣u3)p(u1,u2∣u3)
-
(u2,u3) 联合给出的关于 u1 的信息量等于 u2 给出的关于 u1 的信息量与 u2 已知条件下 u3 给出的关于 u1 的信息量之和。I(u1;u2,u3)=I(u1;u2)+I(u1;u3∣u2)=I(u1;u3)+I(u1;u2∣u3)
非平均自信息量
-
给定一个离散型随机变量 {X,xk,Qk,k=1∼K}
事件 xk∈X 的自信息量定义为
I(xk)=logaQk1
其中底数 a 是大于 1 的常数。
-
非平均自信息量的性质:
- 非负性:I(xk)≥0
- 单调性: Qk 越小,I(xk) 越大
- I(xk;yj)≤min{I(xk),I(yj)},即互信息量不超过各自的自信息量。
-
非平均自信息量 I(xi) 的物理意义
- 当事件 xi 发生前,表示该事件发生的不确定性
- 当事件 xi 发生后 , 表示该事件所提供的信息量
条件的非平均自信息量
- 在事件 yj 发生的条件下事件 xk 的条件自信息量定义
I(xk∣yj)=logaP(x=xk∣Y=yj)1=logaP(xd,yj)Ωj
- 性质:I(xk∣yj)=I(xk)−I(xk;yj)
联合的平均自信息量
-
I(xk,yj)=logaP(xk,yj)1
-
性质:
I(xk,yj)I(xk,yj)=I(yj)+I(xk∣yj)=I(xk)+I(yj∣xk)=I(xk)+I(yj)−I(xk;yj)
-
联合的非平均自信息量实际上是非平均自信息量的简单推广 ——将 (X,Y) 看成一维变量
熵
离散集的平均自信息量——熵
- 熵:H(X)=E[I(x)]=∑k=1Kp(xk)I(xk)=−∑k=1KQklogaQk
- a>1
- 定义 𝟎𝒍𝒐𝒈𝟎=𝟎
- 信息熵单位与自信息量单位相同:Bit,Nat,Det
- 表示了 X 中事件出现的平均不确定性
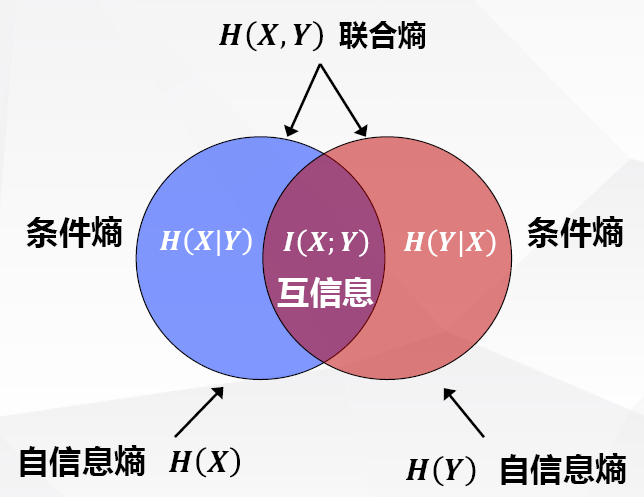
条件熵、联合熵
-
条件熵:H(X∣Y)=−∑k=1K∑j=1Jp(xk,yj)logp(xk∣yk)
-
联合熵:H(X,Y)=−∑k=1K∑j=1Jp(xk,yj)logp(xk,yk)
-
联合熵条件熵的关系
- H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)
- 当 X 与 Y 相互独立时,
H(Y∣X)=H(Y),H(X∣Y)=H(X)
此时也有 H(X,Y)=H(X)+H(Y)
相对熵
-
相对熵:两个随机分布之间的距离
-
两个概率密度函数 p(x) 和 q(x) 之间的相对嫡,或 Kullback-Leibler 距离定义为 :
D(p∥q)=x∈X∑p(x)logq(x)p(x)=Ep(x)logq(x)p(x)
-
约定:0logq0=0,plog0p=∞
-
D(p∥q)=D(q∥p)
-
相对熵的意义:量度当真实分布为 p 而假设分布是 q 时的无效性
-
性质:
- 相对熵总是非负的 ( 信息散度不等式 )
−D(p∥q)=−x∈A∑p(x)logq(x)p(x)=x∈A∑p(x)logp(x)q(x)≤logx∈A∑p(x)p(x)q(x)=logx∈A∑q(x)≤logx∈X∑q(x)=log1=0
- 条件相对熵
D(p(y∣x)∣∣q(y∣x))=x∑p(x)y∑p(y∣x)logq(y∣x)p(y∣x)=Ep(x,y)logq(Y∣X)p(Y∣X)
- 链式法则
D(p(x,y)∥q(x,y))=D(p(x)∥q(x))+D(p(y∣x)∥q(y∣x))
离散集的平均互信息量
-
I(X;Y)=∑XYP(XY)I(x;y)=I(Y;X)=D(p(x,y)∥p(x)p(y))
-
性质:
- I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)=H(X)+H(Y)−H(X,Y)
- I(X;X)=H(X)−H(X∣X)=H(X)
- I(x;y)≤min{H(X),H(Y)}
-
熵是随机变量不确定度的量度
- 条件熵 H(X∣Y) 是给定 Y 之后 X 的剩余不确定度的量度
- 联合熵是 X 和 Y 一起出现时不确定度的量度
- 互信息 I(X;Y) 是给定 Y 之后 X 不确定性减少的程度
-
链式法则:
- 熵:H(X1,X2,…,Xn)=∑i=1nH(Xi∣Xi−1,…,X1)
- 互信息:I(X1,X2,…,Xn;Y)=∑i=1nI(Xi;Y∣Xi−1,…,X1)
熵的宏观理解
-
熵与事件的具体形式无关,仅取决于其概率分布
-
熵必定不小于0
-
如果概率向量中某个分量为 1,说明该事件确定,熵为 0
-
可忽略性:当 qk→0 时 qkloga(qk1)→0
-
极值性:H(x)≤logak 当 q1=q2=⋯=qk=1/k 时,才有
H(X)=logaK
信息不等式
信息不等式
- 凸函数:f(θα+(1−θ)β)≤θf(α)
- 凸函数的线性组合还是凸函数
- 函数 f 总是位于任意一条弦下面
- 凸函数的二阶导数非负(恒正为严格凸函数)
- 概率矢量:矢量的所有分量和为 1
- 基础不等式:lnx≤x−1
- Jensen 不等式
- 若 f 是凸函数,X为随机变量 , 则 E[f(X)]≥f[E(X)]
- 若 f 是严格凸的,则不等式严格成立 ; 除非 X 是个常数 , 即 X=EX 时等号成立
- 若 f 是凹函数,则不等式反向
- 信息散度不等式:D(p∥q)≥0,等号成立当且仅当 p(x)=q(x) 恒成立
- 互信息不等式:I(X;Y)≥0
- 所有的 Shannon 信息度量都可以看成 I(X;Y∣Z) 的特例
相对熵,熵,互信息的凸性
-
最大离散熵定理
设 ∣X∣ 是 X 中的元素数目,则 H(X)≤log∣X∣ ,当等概率时等号成立
-
条件降低熵
H(X∣Y)≤H(X),X 与 Y 独立时等号成立
※:条件作用使熵减小仅在平均意义下成立,某个特定的 H(X∣Y=y) 可能比 H(X) 大
-
对数和不等式
对非负数 a1,a2,…,an 和 b1,b2,…,bn, 有
i=1∑nailogbiai≥(i=1∑nai)log∑i=1nbi∑i=1nai
当且仅当 biai 为常数时等号成立
- 应用:D(p∥q) 是 (p,q) 的凸函数
-
马尔科夫链:P(X,Y,Z)=P(X)P(Y∣X)P(Z∣Y)
-
数据处理不等式:若存在马尔科夫链 X→Y→Z,则 I(X;Y)≥I(X;Z)
-
找不到一个对 Y 进行确定性或随机的处理过程 ,使得 Y 包含 X 的信息量增加
-
Fano 不等式
设已知随机变量 Y, 需要估计和 Y 相关的随机变量X的值,Fano不等式将猜测随机变量 X 的错误概率与条件熵 H(X∣Y) 联系起来
- Pe=Pr{X=X}=0 当且仅当 H(X∣Y)=0
- 不等式:H(Pe)+Pelog(∣X∣−1)≥H(X∣Y)
- 减弱形式:1+Pelog∣X∣≥H(X∣Y) 或 Pe≥log∣X∣H(X∣Y)−1
-
互信息量的凹凸性
- 若 p(y∣x) 给定 , 则 I(X;Y) 是关于 p(x) 的凹函数
- 若 p(x) 给定 , 则 I(X;Y) 是关于 p(y∣x) 的凸函数
渐进均分性
渐进均分性定理
-
弱大数定律:设 X={x1,x2,…,xn,…} 为相互独立的随机变量序列
并服从相同的分布,且有有限数学期望 EXi=a, 则 n1∑i=0n−1Xi 以概 率收敛到 a
-
渐进均分性定理 (AEP : Asymptotic Equipartition Property):
"几乎所有的事件都等概率出现"
对无记忆独立同分布信源 {Xk,k≥1} 有 −n1logp(Xn) 依概率收敛到 H(X)
-
典型集 Aε(n):满足 2−n(H(X)+ε)≤p(Xn)≤2−n(H(X)−ε)
-
性质:
- 若 (x1,x2,…,xn)∈Aε(n), 则
H(X)−ε≤−n1logp(x1,x2,…,xn)≤H(X)+ε
- 当 n 充分大时,Pr{Aε(n)}>1−ε
- ∣Aε(n)∣≤2n(H(X))+ε
- 当 n 充分大时,∣Aε(n)∣≥(1−ε)2n(H(X))−ε
AEP 的结果应用:数据压缩
-
编码方案:
- 将每个集合中的所有元素按某种顺序 ( 如字典序 ) 进行排列。然后通过给予每个序列一 个下标,就可以表示 Aε(n) 中的每一个序列。 由于 Aε(n) 中的序列个数 ≤2n(H(X)+ε), 则这些下标不超过 n(H+ε)+1 比特。在所有的 这些序列前加 0,表示 Aε(n) 中的每一个序列需要的总长度 ≤n(H+ε)+2 比特。
- 对不属于 Aε(n) 中的每个序列给出下标,所需的字节数不超过 nlog∣X∣+1 比特。在这些序列前加 1,就获得了一个关于 Xn 中所有序列的编码方案。
-
用 xn 表示序列 x1,x2,…,xn, 设 l(xn) 是对应于 xn 的码字长度。
-
定理: 设 Xn 为独立同分布序列且服从 p(x),ε>0, 则存在一个将 长度为n的序列 xn 映射到二进制串的编码,使得编码是 “one-to-one” 的(因而可逆 ),且当n充分大时,有
E[n1l(Xn)]≤H(X)+ε
- 从平均意义上讲,用 nH(X) 比特就可以表示序列 Xn
熵界
熵和平均码长
- 熵界:信源 S 的任一 r 元即时码的平均码长必大于等于熵 Hr(X), 其中等号成立当且仅当 pi=r−li
- 解释 : 信源 s 发射的每个符号平均携带 Hr(S) 个信息单元 ; 如果要在不丢失任何信息的情况下对 S 进行编码,则码 C 必须是唯一可译码 ; 每个码字符号传达一个信息单元 , 因此平均每个码字必须至少包含 Hr(S) 个码字符号,也就是说 L(C)≥Hr(S)
- 编码效率:η=L(C)Hr(S)
- 冗余度: ηˉ=1−η
几种典型的信源编码
Shannon-Fano 编码
- Shannon-Fano 编码:由 Kraft 不等式,存在的满足码长条件的即时码 C
- 可以估算平均码长(Huffman 不行)
- Hr(S)≤L(C)<1+Hr(S)
- 不知道如何构造
Shannon-Fano-Elias 编码
- 思路:利用累积分布函数来分配码字
- 设字母集 X,假设对 x∈X,p(x)>0
- 累积分布函数:F(x)=∑x≥ap(x)
- 修正的累计分布函数 Fˉ(x)=∑x≥ap(a)+21p(x)
- 设 Fˉ(x)=0.a1a2a3…al(x)al(x)+1…
- 码长 l(x)=[logp(x)1]+1,用 [Fˉ(x)]l(x) 表示小数点后 l(x) 位,则码字为 [Fˉ(x)]l(x)
- 平均码长:Lˉ<H(x)+2,只比最优值多了 2 bit
算术编码方法
- 上述编码都是建立在信源符号于码字一一对应的基础上的,被称为块码,而要对序列进行编码,则需要从整个序列出发,采用递推形式进行编码
- 基本方法:
- 寻找一个计算 xn 的概率分布 p(xn) 和累积分布函数 F(xn) 的快速算法
- 利用 Shannon-Fano-Elias 方法进行编码:用 [F(xn)−p(xn),F(xn)] 中的一个二进制数表示 xn 码字
- 以二元序列为例
- 编码:F(xn)=∑yn≤xnp(yn)=∑T子树在xn的左侧p(T)+p(xn),码长为 [logp(xn)1]
- 译码:从收到的码字计算相应的 F(xn),从根节点开始比较 F(xn) 和 p(0)
- 如果 F(xn)>p(0),则从 0 往下的子树在 xn 的左边,第一位是 1,反之是 0
- 如果已经译出 x1=0,则继续比较 F(xn) 和 p(00),以此类推
- 优点
- 编码效率高:当序列很长时,η 接近 1
- 需要参数少,编码译码简单,没有哈夫曼那样的大码表
- 实际使用时,如果编码使用的是非真实分布,平均长度会增加 D(p∥q)
香农第一定理
信源的扩张
- 扩展信源:S={s1,…,sq} 的 n 次扩展信源的消息集合为 Sn={s11,…,s1n,sq1,…,sqn}
- 可以看作是 n 个 S 的乘积
- 乘积:对于消息集合 S,T,S×T={si,tj}
- 如果 S,T 独立,则 Hr(S,T)=Hr(S)+Hr(T)
- 单位消息的平均码长随着信源扩张不断降低
香农第一定理
- Shannon 信源编码定理、可变长无失真信源编码定理:通过对 n 足够大的 Sn 进行编码,总可以找到信源 S 的一个 r 元即时码,其对应 S 的平均码长可以与 Hr(S) 任意接近
- 是一个存在性定理
LZ 编码
- 比 Huffman 编码更高效,比算术编码更快捷的算法
LZ78
-
是一种分段编码算法,编码是将输入信源序列分段:
- 首先,取一个符号作为第一段
- 然后继续分段,若有符号与前面符号相同时,就再取紧跟后面的一个符号一起组成一个段,使之与前面的段不同
- 当字典达到一定大小,再分段就应查看是否与字典中已有符号相同,若有重复就添加符号后查看,直至与字典中短语不同为止
-
分段规则:尽可能取最少个相连的信源符号,并保证各段都不相同
-
设信源符号集 A={a1,a2,…,ak} ,输入信源符号序列为 u=(u1,u2,…,uL),其中 ui∈A,编码时 u 按照规则进行分段
-
设分段结果为 {y1,y2⋯,yc} 构成字典,则 yj∈A 或有 yj=yiar(i<j),所以编码码字可以用段号 i 和符号序号 r 组成
- 仅包含单符号的短语段号为 0,非单字符短语的为除最后一个符号外字典中相同短语的段号
-
编码码字为 Nj=i∗k+r
- 段号所需码长 [logc],符号序号所需码长为 [logK]
- 总码长 c([logc]+[logK]),平均码长 Lc([logc]+[logK])
-
定理:随着输入序列增长,LZ 的编码效率提高,平均码长会逼近信源熵
信道
信道
graph TD
A[信源A]--输入端-->B[信道]
B--输出端-->C[信宿B]
D[干扰]-->B
信道分类
根据输入输出时间的时间特性和输入分类
- 离散信道:A 和 B 都是离散事件集合
- 连续信道:A 和 B 都是连续事件集合
- 半连续信道:A 和 B 一个是离散事件集合,一个是连续事件集合
- 时间离散的连续信道:信道的输入和输出是取决于连续集合的序列
- 波形信道:信道输入和输出是随机过程
根据输入和输出个数
- 两端信道:输入输出只有一个事件集合
- 多端信道:输入和输出至少有一段有两个以上的事件集合
根据统计特性
- 恒参信道:信道的统计特性不随时间变化
- 随参信道:信道统计随时间变化
根据记忆特性
- 无记忆信道:输出集仅取决当前输入集
- 有记忆信道:输出集与当前和以前若干个输入集有关
传播路线
有无噪声
有无损
离散信道模型
- 信道输入事件的概率空间为
[A={a1,…,ar}P={pi=p(a=ai)}]
- 信道输出事件的概率空间为
[B={b1,…,bs}Q={qj=p(b=bj)}]
- 信道相当于一个数学交换,可以用条件概率描述
pij=p(b=bj∣a=ai)=p(bj∣ai)
离散无记忆信道 DMC
p(y∣x)=p(y1y2…yN∣x1x2…xN)=i=1∏Np(yi∣xi)
则称其为离散无记忆信道,记作 [Xp(yi∣xi)Y]
平稳信道(恒参信道)
- 若 DMC 对于任意给定的 n 和 m 有
p(yn=bj∣xn=ai)=p(ym=bj∣xm=ai)
则称为平稳信道,即信道转移概率不随时间变化
信道矩阵
几种典型有扰离散信道
二进制对称信道
- BSC
- P=[1−εεε1−ε]
- 对称信道:所有行/列都是第一行/列的置换
二进制删除信道(BEC)
公式和定义
香农第一定理的推广
- 给定信道输出 B 的知识下,对信道输入 A 的唯一可译码的平均码长下界为 H(A∣B)
信道容量的定义与计算
信道组合
积信道(并联信道)
-
两个以上信道并行使用
-
信道容量 C=C1+C2
-
最佳输入分布
{(x,u),q1(x)q2(u)}
和信道(合信道)
-
两个以上信道交替使用
-
信道容量 C=log(2C1+2C2)
-
最佳输入分布
{x,2C1+2C22C1q1(x)}
{u,2C1+2C22C2q2(u)}
级联信道(串联信道)
- 两个以上信道串联使用
- 信道容量 C≤max{C1,C2}
译码规则和联合 AEP
译码规则
- 信道容量描述了一个信道单位时间可以传输的最大信息量,但是未保证信息传输的无差错性
- 译码规则:对每一个输出符号 yi 都有一个确定函数 Δ(yi) ,使 yi 对应唯一的一个输入符号 xi,这样的一族函数,称为译码规则
- 对于有 r 个输入,s 个输出的信道而言,译码规则有 rs 种
- 译码错误概率:在确定 Δ(yi)=xi 后,若信道输出端接收到符号 yi,则译为 xi
- 如果发送端发送的就是 xi,译码正确,正确概率为 p(xi∣yi)
- 如果发送端发送的不是 xi,译码错误,错误概率为 1−p(xi∣yi)
- ※:注意是 yi 下的条件概率,所以往往需要使用贝叶斯公式
- 平均译码错误概率:PE=∑Yp(yj)pE(yj)
- 最优译码规则:平均译码错误概率最小的译码规则
- 最大后验概率准则(理想观测者准则):对于收到的的符号 yj,译码规则 Δ(yj)=x∗,使之满足条件 p(x∗∣yj)≥p(xi∣yj)(i=1,2,…,r)
- 所有译码规则中,最大后验概率准则的 PE 最小
- 极大似然译码准则(大数逻辑译码准则):对于收到的的符号 yj,译码规则 Δ(yj)=x∗,使之满足条件 p(yj∣x∗)p(x∗)≥p(yj∣xi)p(xi)(i=1,2,…,r)
编码方法和错误概率
汉明码和线性码
- 信道编码定理仅给出了码的存在性,没有说明如何获得工程上的好码,这是几十年努力的目标:码长尽量短;码字具有规律
汉明码
- 码重:二进制序列中 1 的个数
- 汉明距离:两个二进制序列中对应位不相等的个数
- 二元汉明码 Ham (r,2) 的译码方式
- 根据二进制表示的列向量从 1 到 n=2r−1 排列得到奇偶校验矩阵 H
- 设由信道接收到消息 x, 计算 S(x)=xHT
- 如果 S(x)=xHT=0, 则没有错误发生
- 否则,则有一个错误发生 ,S(x) 即为错误位置的二进制表示,将错误位置 上的值改变即可
- 一般地 : 前 k 个比特代表消息,后面 n−k 个比特留作奇偶校验位,这样得到的码通常称为系统码
- 码由分组长度 n, 信息比特数 k 以及 最小距离 d 三个参数确定
- 二元汉明码 Ham (r,2) 的译码参数
- 码长:n=2r−1
- 校验位个数:r
- 信息位个数:k=n−r=2r−1−r
- 最小码字长度:d=W(C)
- 纠错能力:t=[2t−1]
线性码
-
定理: q 元汉明码Ham (r,q) 是 q 元 (n,n−r,3) 线性码,其中
n=(qr−1)/(q−1)
-
现考虑 F 上码长为 n 的码,则这种码的码字集合是 Fn 的一个子集,注意是 F 上 的 n 维向量空间
如果码 C 的码字集合构成 Fn 的一个线性子空间,设此线性空间维数为 k, 此时将码 C 记作 (n,k) 线代码
-
如果线性码 C 的生成矩阵 G 的标准形式为 G=(Ik∣P), 则 C 的一个校验矩阵形如 H=(−PT∣In−k)
-
线性码的编码方式:设G为 q 元 (n,k) 线性码 C 的生成矩阵 , 如果信源消息 x 为 Fk 的一个向量 , 则对 任意 x∈Fk, 将其编码为 xG
-
线性码的译码方式:
- 列表法:按如下方式构造列表
- 表的第1行为 L 中所有码字,且 0 排在第1位 (0+L)
- 对第 i 行,首先选取不在先前 i−1 行中出现且重量最小的 vi∈Fn, 令第 i 行 的所有元素为 vi+L, 且其余元素按照第1行中非零码字的排列顺序进行排列,使得每行元素互不相交
- 重复以上步骤,直到排完 Fn 的所有元素 , 最终该表共有 qkqn=qn−k 行,称作标准阵 (vi 为陪集头 )
- 设线性码的最小距离为 d, 则令 t=⌊2d−1] 为码的纠错个数,在重量为 wt(vi)≤t 的最后一行后划一条横线作为标记
- 利用伴随式进行解码
- 将列表简化,仅保留两列:陪集头及其伴随式
- 设接收到 v, 则计算其伴随式 vHT ,在上述伴随式表中寻找伴随式与 xHT 相的陪集头 vi
- 将v译为 v−vi
译码错误概率和不可检错误概率